
- 분류 전체보기 (216)

Notice
Recent Posts
Recent Comments
Link
Douglas' Space
Semi-Supervised Learning 본문
labeled data를 만드는 것은 많은 비용이 투자되는 작업이라는 것은 계속 설명드리고 있기 때문에 모든 분이 충분히 이해하실 것이라 생각합니다. 그래서 지난 시간에 전이학습이나 자기주도학습에 대한 이야기를 했습니다. 오늘 이러한 관점에서 적은 데이타로 성능을 올릴 수 있는 또 다른 방법인 semi supervised learning(SmSL), 준지도학습에 대해 살펴보도록 하겠습니다.
우리가 labeled data를 많이 확보하려는 이유는 무엇인가요? 근본적인 것은 모델의 성능을 높이기 위한 것입니다. 따라서 labeled data를 만드는 비용이 많이 들거나 불가능한 경우에 우리가 할 수 있는 방법은 모델의 성능을 높이기 위해 labeled data를 만들지 않고 성능을 높일 수 있는 방법입니다. labeled data를 이용하지 않고 모델의 성능을 높이는 방법에도 크게 2가지 정도 생각할 수 있는데, 한가지가 Hyper parameter를 조정하는 것이고 또 다른 한가지는 unlabeled data를 활용하여 성능을 높이는 방법입니다. SmSL은 후자와 같은 unlabeld data를 활용하는 방법이라고 할 수 있습니다.
아래 그림의 왼쪽은 적은 labeled data를 가진 모델의 성능을 표현하고 있습니다. 오른쪽은 unlabeled data(녹색원)를 이용하여 그 성능을 높인 결과의 모델의 성능을 표현하고 있습니다. SmSL의 의도를 간단히 표현한 그림이라고 할 수 있습니다. 왼쪽의 모델 상태에서 unlabeled data로 예측을 하면 틀리는 경우가 많지만, SmSL를 적용한 결과인 오른쪽 모델은 예측의 성능이 더 좋아진 것을 알 수 있습니다.
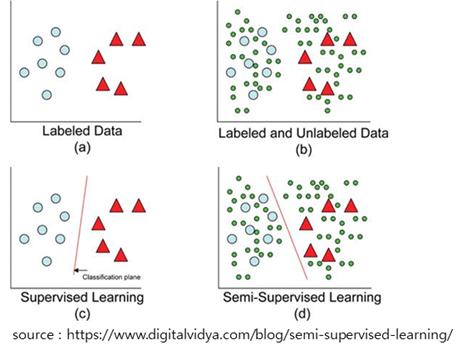
SmSL의 대표적인 방법이 consistency regularization입니다. 이 방법은 지난번 자기주도학습에서 대표적으로 설명한 data augmentation, 즉 데이타를 변형하여 원본 데이터와 변형된 데이터를 적용한 loss function의 결과의 차이가 최소가 되도록 학습하는 방법입니다.
또 따른 대표적인 방법으로 entropy minimization이라는 방법입니다. 용어들이 어렵죠. 그냥 이런 용어들과 방법이 있구나 정도만 이해하시면 될 것 같습니다. 정보이론에서의 entropy를 간단히 설명하면, 거의 발생하지 않는 사건이 발생했다는 정보는 엄청난 정보의 가치를 갖지만, 확률은 매우 낮다는 것을 의미하며 이러한 정보의 총 가치의 평균을 entropy라고 합니다. 예를 들어 개와 고양이를 분류하는데 개 0.6, 고양이 0.4가 나오는 것보다 개 0.9, 고양이 0.1이 나오는 것이 entropy가 더 낮고 이러한 방향으로 학습이 진행되도록 한다는 의미입니다. 다시 말해 unlabeled data의 가상정답l(pseudo label)을 적용할 때 유사도가 높은 방향으로 최대치를 부여한다는 의미와 같습니다.
보통은 이러한 기법을 통합적으로 적용한 MixMatch와 같은 방법을 많이 활용 합니다. 결론적으로 준지도학습은 labeled data가 적을 때 unlabled data를 같이 혼용하여 모델의 성능을 극대화 하는 방법입니다. 지난번 소개한 자기주도학습도 성능을 높이기 위해 적용하는 경우라면 내용면에서 같다고 할 수 있습니다. 그러나 자기주도학습은 unlabled data 만을 가지고 전체 문제를 해결하려는 의미에서 unsupervised learning의 한 방법으로 이해하는 것으로 해석하는 것이 맞을 것 같습니다.
'Computing Tech. Diary > Artificial Intelligence' 카테고리의 다른 글
| 자연어처리를 위한 word embedding (0) | 2022.05.02 |
|---|---|
| Transformer (0) | 2022.05.02 |
| Self-Supervised Learning (0) | 2022.05.02 |
| Transfer Learning (0) | 2022.05.02 |
| 불균형 데이터(imbalanced data)란 (0) | 2022.05.02 |
'Computing Tech. Diary/Artificial Intelligence' Related Articles
more




Comments