
Notice
Recent Posts
Recent Comments
Link
Douglas' Space
강화학습 이해하기 본문
혹시 딥러닝을 몰라도 강화학습을 아는 분이 더 많지 않나 생각합니다. 강화학습을 사용한 알파고라는 놈때문이죠. 강화학습은 비지도학습과 같이 자기스스로 학습하는 기계학습의 한 방법입니다. 그럼 비지도학습에 포함하지 않고 왜 별도로 강화학습이라고 분류할 까요?
지도학습과 비지도학습을 구분하는 것은 정답이 있는 데이터(labelled data)를 사용하느냐 정답이 없는 데이터(unlabelled data)만 사용하느냐로 결정됩니다. 그런데 강화학습은 특별히 데이타를 이용하여 학습을 하는 경우가 아니라 최적의 의사결정을 위해 시행착오를 통해 학습하기 때문에 스스로 학습하지만 비지도학습과 구분하여 별도로 분류한 것 같습니다.
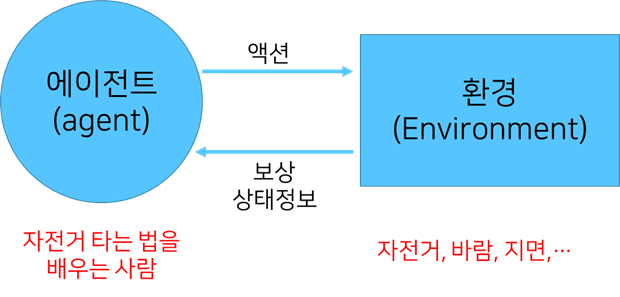
위 그림은 강화학습의 기본개념 및 용어에 대해 설명한 그림입니다. 에이전트는 학습을 수행하는 객체입니다. 환경은 상태에 영향을 주는 주변의 다른 객체들 이라고 할 수 있습니다. 자전거 타는 법 배우기에서 배우는 사람이 에이전트라면 자전거 타는 것에 영향을 주는 환경은 자전거, 바람, 지면 등이 있을 것입니다. 자전거를 타기 위해서는 페달을 밟고, 핸들을 움직이는 어떤 행동을 취하게 됩니다. 그러면 이에 대해 넘어지지 않고 잘 가는 경우는 보상을 받고, 넘어지는 경우는 보상을 받지 못하게 됩니다. 다시 말해 자전거 타는 법을 배우는 사람은 자기가 한 행동에 대한 보상이 최대가 되는 방향으로 행동을 취하도록 학습을 한다는 것입니다.
에이전트는 어떤 상태에서 임의의 액션을 취하고, 이 액션에 따라 환경은 보상과 상태에 영향을 주는 정보를 주게되며, 에이전트는 보상이 최대가 되는 방향으로 액션을 취하게 됩니다. 액션과 상태 등은 이산적인 값일 수도 있지만 연속적인 값일 수도 있습니다. 강화학습은 사용하는 알고리즘에 따라 구분하기 때문에 강화학습의 종류를 이해하는 것은 매우 기술적인 이해를 필요로 합니다.
강화학습에서 가장 기초적인 기술적 개념 및 용어로는 MDP(Markov Decision Process), Episode와 Expected Return의 개념입니다. MDP의 핵심개념은 현재 시점의 상태는 바로 전 시점의 상태와 액션에 의해서만 결정된다는 것입니다. 예를 들어 운전을 할 때 과거에 어떠한 경로를 따라 운전을 해왔더라도 t+1시점의 차의 위치는 t시점에서의 차의 위치와 액션에 따라 결정된다는 것입니다.
episode는 초기상태에서 종료상태까지 에이전트가 수행한 하나의 시퀀스를 의미합니다. A라는 지점에서 B라는 지점을 운전한다고 할때 A라는 지점이 초기 상태, B라는 지점이 종료상태라고 할 수 있습니다. 이때 종료지점까지는 다양한 경로가 존재하며, 이 임의의 한 경로를 운전하는 것을 episode라고 할 수 있습니다. 이러한 episode를 여러 번 반복하면서 최적의 경로를 찾는 것입니다. 각 epsode마다 종료상태에서 보상을 받습니다.
expected return이란 임의의 상태에서 종료상태까지의 얻을 수 있는 보상의 평균값이라고 할 수 있습니다. 따라서 에이전트는 expected return이 최대가 되도록 액션을 선택하며 episode를 수행합니다. 이렇게 에이전트가 episode를 계속 반복하면 최적의 해를 구하게된다는 개념입니다. 운전의 예에서 특정 경로에서 임의의 지점에서 종료지점까지 기대되는 보상값을 의미합니다.
강화학습의 응용분야로는 알파고와 같은 게임분야, 복잡한 지형에서도 자세를 유지하는 지능형 로봇분야, 현재 상태에서 가장 최적의 행동을 찾는 자율주행분야 등을 들 수 있습니다. 특히 알파고를 더 진화시켜 알파고제로, 알파제로 등을 발표하는 딥마인드에서는 지난 5월 24일에는 강화학습만으로 AGI(Artifitical General Intelligence)를 달성할 수 있을 것이라고, “보상이면 충분하다”라는 주제의 논문을 발표하기도 하였습니다.
'Computing Tech. Diary > Artificial Intelligence' 카테고리의 다른 글
| 불균형 데이터(imbalanced data)란 (0) | 2022.05.02 |
|---|---|
| Semantic Segmentation (0) | 2022.05.02 |
| GAN 신경망을 통해 이해하는 딥러닝 (0) | 2022.04.30 |
| RNN 신경망을 통해 이해하는 딥러닝 (0) | 2022.04.30 |
| CNN 신경망을 통해 이해하는 딥러닝 (0) | 2022.04.28 |
'Computing Tech. Diary/Artificial Intelligence' Related Articles
more




Comments