
- 분류 전체보기 (284)

Notice
Recent Posts
Recent Comments
Link
Douglas' Space
GAN 신경망을 통해 이해하는 딥러닝 본문
“인공지능이 당신의 일자리를 노리고 있습니다.” 라는 신문기사를 많이 보셨을 것 같습니다. 5년전 알파고의 쇼크로 사회에 이슈가 되던 해, 2016년, 한국고용정보원에서는 400여개의 주요 직업 가운데 인공지능과 로봇으로 인해 대체될 직업의 확률을 분석한 결과를 발표한 적이 있습니다. 이 중에 대체될 확률이 가장 낮았던 직업이 화가 및 조각가, 작가 및 사진작가 등 이었습니다.
그런데 2018년 미국 뉴욕 크리스티경매에서 최초의 인공지능이 창작한 그림이 경매에 나와 고가에 낙찰되었다는 기사가 많은 사람에게 회자되었습니다. “인공지능 창작활동, 예술의 위기인가 …”라는 식의 신문기사를 또 한번 접하게 됩니다. 어떻게 이런 일이 가능한 걸까요? 정말 인공지능이 사람처럼 지능을 가진 걸까요?
제가 지금까지 연재하는 인공지능의 이야기가 어렵다는 분들이 많은 것 같습니다. 가능한 쉽게 이해를 돕는 측면에서 글을 쓰지만 글의 취지가 기본적인 원리를 이해하여 오해가 없기를 바라는 마음에 기술적인 부분을 설명드리다 보니 어려워 지는 것 같습니다. 물론 어디까지 이해를 해야 하는 것인가에 대해 생각이 다를 수 있겠지만, 의사결정에서의 실수를 가능한 최소화하는 범위로 저는 생각하고 있습니다.
처음 기계학습이라는 말이 나올 때 뉴스기사에서는 거의 인간을 대체할 것 같은 기사들이 쏟아졌고, 많은 사람들이 허황된 꿈과 사기(?)에 가까운 이야기 듣고 의사결정을 하여 시간과 자원을 낭비하였기 때문입니다. 마치 돌팔이 의사가 하는 이야기를 듣고 건강, 시간, 돈을 낭비하는 것과 같다고 할 수 있습니다.
다시 원 주제로 돌아와 보겠습니다. 이러한 창작하는 인공지능의 실체가 되는 ANN이 GAN(Generative Adversarial Networks)입니다. 우리 말로는 생성적 적대신경망 정도로 해석합니다. GAN은 앞서 설명한 CNN, RNN과 달리 비지도학습 위주의 딥러닝 기술입니다. (즉 정답을 위한 labeled data가 필요하지 않음) 기본 원리는 아래 그림과 같습니다.
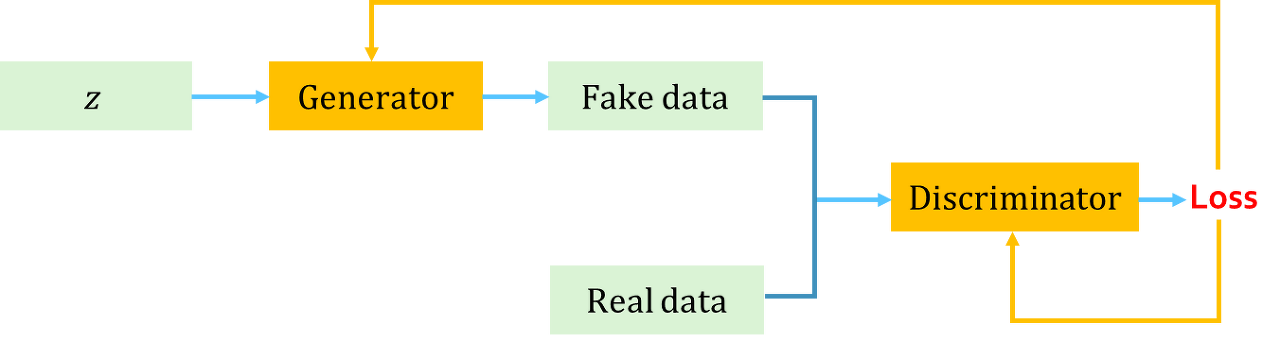
위 그림의 GAN은 크게 2개의 신경망으로 구성됩니다. 하나는 Generator(생성자, G)라는 놈과 Discriminator(구분자, D)라는 놈으로 구성되어 있습니다. 이 둘중에 G라는 놈이 창작을 하는 놈입니다. G에 입력되는 Z(초기에는 임의의 데이타)를 이용하여 Fake data(가짜데이터)를 임의로 생성합니다. D는 G가 생성한 가짜데이터와 real data(실제데이터)를 입력을 받아 가짜와 진짜를 구분합니다.
보통 이를 설명하는데 위조지폐범과 위조지폐를 감별하는 사람을 비교하여 설명합니다. G인 위조지폐범은 위조지폐를 만들어 시장에 뿌리고 감별사가 이를 구분하는지를 잘 보고 걸리면 왜 걸렸는지 알아서 이를 수정하여 새로운 위조지페를 만드는 과정을 반복합니다. 이러다 보면 진폐와 같은 위폐를 만들어 내게 됩니다.
따라서 GAN에서 처음에 G는 아주 말도 안되는 결과를 생성합니다. 그러다 D가 구분한 결과를 활용하여 시간이 점점 지나면서 진짜와 같은 데이터를 생성하게 됩니다. 예를 들어 그림을 창작하는 GAN에 대해 한번 생각해 보겠습니다. D가 유명한 화가의 그림 들로 진짜 그림을 진짜라고 학습합니다. 그리고 G는 처음에 노이즈 데이터를 이용하여 그림같지 않은 그림을 생성합니다. D는 G가 생성한 그림을 보고 가짜 임을 당장 구분할 수 있습니다. G는 D가 구분한 결과를 가지고 학습을 하고 다시 그림을 생성합니다. 이 작업을 G의 그림이 D가 진짜라고 구분할 때까지 반복 수행합니다. 최종적으로 G는 진짜와 같은 가짜 그림을 창작하게 됩니다.
구분자인 D는 기존의 학습방법으로 이해되지만 생성자 G는 사실 어떻게 그림을 생성하는 것인지가 사실 이해하기 어려운 부분입니다. 이 부분은 확률(특히 확률분포)에 대한 개념을 조금만 이해하시면 간단히 이해할 수 있습니다. ANN은 함수들의 집합이라고 설명 드렸던 것처럼 D는 확률분포를 생성하는 확률함수인 확률밀도함수(PDF)라는 것을 활용하는 것입니다. 인간처럼 영감으로 창작하는 것이 아니라 모방하고 변형한다는 의미이며 결국 수학으로 모델링하는 것이라 생각하시면 됩니다. 다시 말해 진짜 데이터들이 갖는 값들의 확률분포와 유사한 확률분포를 학습하여 이 분포에서 데이터를 샘플링한다는 의미입니다.
지금은 애플에서 일하는 것으로 알려진 Ian Goodfellow라는 사람이 2014년에 제안한 이래 가장 많은 변종들이 만들어지는 ANN이라고 할 수 있습니다. CycleGAN이라는 것은 그림을 가지고 사진을 만들어주고, 사진을 가지고 유명한 화가의 그림풍으로 그림을 생성해 줍니다. 겨울 사진을 가지고 동일한 여름 사진을 만들기도 합니다. StackGAN은 문장을 주면 이 문장에 해당하는 사진을 생성하기도 하고, ProgessiveGAN은 저해상도 이미지로 부터 고해상도 이미지를 생성하기도 합니다. StyleGAN 같은 경우는 머리, 연령, 성별을 고려하여 고품질의 얼굴 사진을 만들어 주기도 합니다. 따라서 GAN을 이용해서 부족한 학습데이터를 보충하기 하기 위해 학습용 데이터를 생성할 수도 있습니다.
'Computing Tech. Diary > Artificial Intelligence' 카테고리의 다른 글
| Semantic Segmentation (0) | 2022.05.02 |
|---|---|
| 강화학습 이해하기 (0) | 2022.04.30 |
| RNN 신경망을 통해 이해하는 딥러닝 (0) | 2022.04.30 |
| CNN 신경망을 통해 이해하는 딥러닝 (0) | 2022.04.28 |
| 데이타가 없으면 AI시스템을 개발할 수 없는가? (0) | 2022.04.28 |
'Computing Tech. Diary/Artificial Intelligence' Related Articles
more




Comments